 This tutorial will show you how to extend Norconex HTTP Collector using Java to create a link checker to ensure all URLs in your web pages are valid. The link checker will crawl your target site(s) and create a report file of bad URLs. It can be used with any existing HTTP Collector configuration (i.e., crawl a website to extract its content while simultaneously reporting on its broken links). If you are not familiar with Norconex HTTP Collector already, you can refer to our Getting Started guide.
This tutorial will show you how to extend Norconex HTTP Collector using Java to create a link checker to ensure all URLs in your web pages are valid. The link checker will crawl your target site(s) and create a report file of bad URLs. It can be used with any existing HTTP Collector configuration (i.e., crawl a website to extract its content while simultaneously reporting on its broken links). If you are not familiar with Norconex HTTP Collector already, you can refer to our Getting Started guide.
The link checker we will create will record:
- URLs that were not found (404 HTTP status code)
- URLs that generated other invalid HTTP status codes
- URLs that generated an error from the HTTP Collector
The links will be stored in a tab-delimited-format, where the first row holds the column headers. The columns will be:
- Referrer: the page containing the bad URL
- Bad URL: the culprit
- Cause: one of “Not Found,” “Bad Status,” or “Crawler Error”
One of the goals of this tutorial is to hopefully show you how easy it is to add your own code to the Norconex HTTP Collector. You can download the files used to create this tutorial at the bottom of this page. You can jump right there if you are already familiar with Norconex HTTP Collector. Otherwise, keep reading for more information.
Get your workspace setup
To perform this tutorial in your own environment, you have two main choices. If you are a seasoned Java developer and an Apache Maven enthusiast, you can create a new Maven project including Norconex HTTP Collector as a dependency. You can find the dependency information at the bottom of its download page.
If you want a simpler option, first download the latest version of Norconex HTTP Collector and unzip the file to a location of your choice. Then create a Java project in your favorite IDE. At this point, you will need to add to your project classpath all Jar files found in the “lib” folder under your install location. To avoid copying compiled files manually every time you change them, you can change the compile output directory of your project to be the “classes” folder found under your install location. That way, the collector will automatically detect your compiled code when you start it.
You are now ready to code your link checker.
Listen to crawler events
There are several interfaces offered by the Norconex HTTP Collector that we could implement to achieve the functionality we seek. One of the easiest approaches in this case is probably to listen for crawler events. The collector provides an interface for this called ICrawlerEventListener. You can have any number of event listeners for your crawler, but we only need to create one. We can implement this interface with our link checking logic:
package com.norconex.blog.linkchecker;
public class LinkCheckerCrawlerEventListener
implements ICrawlerEventListener, IXMLConfigurable {
private String outputFile;
@Override
public void crawlerEvent(ICrawler crawler, CrawlerEvent event) {
String type = event.getEventType();
// Create new file on crawler start
if (CrawlerEvent.CRAWLER_STARTED.equals(type)) {
writeLine("Referrer", "Bad URL", "Cause", false);
return;
}
// Only keep if a bad URL
String cause = null;
if (CrawlerEvent.REJECTED_NOTFOUND.equals(type)) {
cause = "Not found";
} else if (CrawlerEvent.REJECTED_BAD_STATUS.equals(type)) {
cause = "Bad status";
} else if (CrawlerEvent.REJECTED_ERROR.equals(type)) {
cause = "Crawler error";
} else {
return;
}
// Write bad URL to file
HttpCrawlData httpData = (HttpCrawlData) event.getCrawlData();
writeLine(httpData.getReferrerReference(),
httpData.getReference(), cause, true);
}
private void writeLine(
String referrer, String badURL, String cause, boolean append) {
try (FileWriter out = new FileWriter(outputFile, append)) {
out.write(referrer);
out.write('\t');
out.write(badURL);
out.write('\t');
out.write(cause);
out.write('\n');
} catch (IOException e) {
throw new CollectorException("Cannot write bad link to file.", e);
}
}
// More code exists: download source files
}
As you can see, the previous code focuses only on the crawler events we are interested in and stores URL information associated with these events. We do not have to worry about other aspects of web crawling in that implementation. The above code is all the Java we need to write for our link checker.
Configure your crawler
If you have not seen a Norconex HTTP Collector configuration file before, you can find sample ones for download, along with all options available, on the product configuration page.
This is how we reference the link checker we created:
<crawlerListeners>
<listener class="com.norconex.blog.linkchecker.LinkCheckerCrawlerEventListener">
<outputFile>${workdir}/badlinks.tsv</outputFile>
</listener>
</crawlerListeners>
By default, the Norconex HTTP Collector does not keep track of referring pages with every URL it extracts (to minimize information storage and increase performance). Because having a broken URL without knowing which page holds it is not very useful, we want to keep these referring pages. Luckily, this is just a flag to enable on an existing class:
<linkExtractors>
<extractor class="com.norconex.collector.http.url.impl.HtmlLinkExtractor"
keepReferrerData="true" />
</linkExtractors>
In addition to these configuration settings, you will want to apply more options, such as restricting your link checker scope to only your site or a specific sub-section or your site. Use the configuration file sample at the bottom of this page as your starting point and modify it according to your needs.
You are ready
Once you have your configuration file ready and the compiled Link Checker listener in place, you can give it a try (replace .bat with .sh on *nix platforms):
collector-http.bat -a start -c path/to/your/config.xml
The bad link report file will be written at the location you specified above.
Source files
![]() Download the source files used to create this article
Download the source files used to create this article
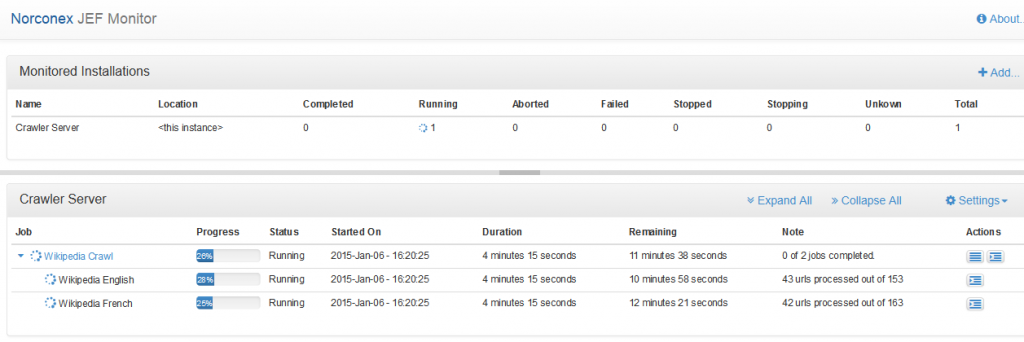

 As a Search Expert at Norconex, I am often assigned the task of integrating web accessibility standards within a search user interface for our customers in the government sector; these customers look to web accessibility to improve the overall search experience of their current enterprise’s search offering. And, of course, we have noticed a growing trend in the desire for search user interfaces that can respond to various screen sizes on various devices.
As a Search Expert at Norconex, I am often assigned the task of integrating web accessibility standards within a search user interface for our customers in the government sector; these customers look to web accessibility to improve the overall search experience of their current enterprise’s search offering. And, of course, we have noticed a growing trend in the desire for search user interfaces that can respond to various screen sizes on various devices.

 Norconex Commons Lang
Norconex Commons Lang