Introduction
You already know that Solr is a great search application, but did you know that Solr 5 could be used as a platform to slice and dice your data? With Pivot Facet working hand in hand with Stats Module, you can now drill down into your dataset and get relevant aggregated statistics like average, min, max, and standard deviation for multi-level Facets.
In this tutorial, I will explain the main concepts behind this new Pivot Facet/Stats Module feature. I will walk you through each concept, such as Pivot Facet, Stats Module, and Local Parameter in query. Once you fully understand those concepts, you will be able to build queries that quickly slice and dice datasets and extract meaningful information.
Applications to Download
- Solr 5.0.0
- Java 7 or higher (Solr 5 needs Java Runtime version 7 and above)
Facet
If you’re reading this blog post, you’re probably already familiar with the Facet concept in Solr. A facet is a way to count or aggregate how many elements are available for a given category. Facets also allow users to drill down and refine their searches. One common use of facets is for online stores.
Here’s a facet example for books with the word “Solr” in them, taken from Amazon.
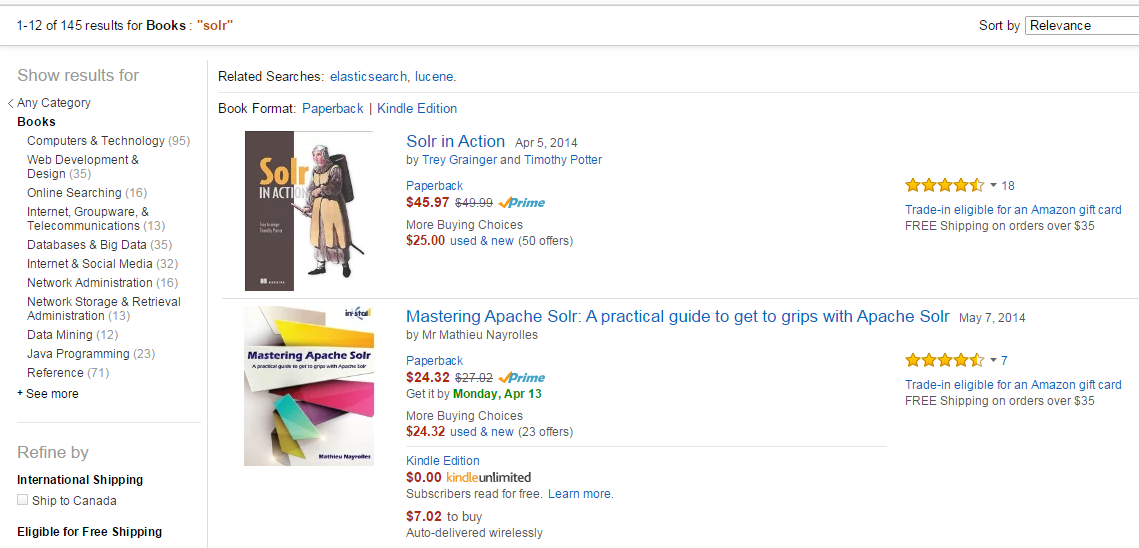
To understand how Solr does it, go on the command line and fire up the techproduct example from Solr 5 by executing the following command:
pathToSolr/bin/solr -e techproducts
If you’re curious to know where the source data are located for the techproducts database, go to the folder pathToSolr/example/exampledocs/*.xml
Here’s an example of a document that’s added to the techproduct database.
Notice the cat and manu field names. We will be using them in the creation of facet.
<add><doc> <field name="id">MA147LL/A</field> <field name="name">Apple 60 GB iPod with Video Playback Black</field> <field name="manu">Apple Computer Inc.</field> <!-- Join --> <field name="manu_id_s">apple</field> <field name="cat">electronics</field> <field name="cat">music</field> <field name="features">iTunes, Podcasts, Audiobooks</field> <field name="features">Stores up to 15,000 songs, 25,000 photos, or 150 hours of video</field> <field name="features">2.5-inch, 320x240 color TFT LCD display with LED backlight</field> <field name="features">Up to 20 hours of battery life</field> <field name="features">Plays AAC, MP3, WAV, AIFF, Audible, Apple Lossless, H.264 video</field> <field name="features">Notes, Calendar, Phone book, Hold button, Date display, Photo wallet, Built-in games, JPEG photo playback, Upgradeable firmware, USB 2.0 compatibility, Playback speed control, Rechargeable capability, Battery level indication</field> <field name="includes">earbud headphones, USB cable</field> <field name="weight">5.5</field> <field name="price">399.00</field> <field name="popularity">10</field> <field name="inStock">true</field> <!-- Dodge City store --> <field name="store">37.7752,-100.0232</field> <field name="manufacturedate_dt">2005-10-12T08:00:00Z</field> </doc></add>
Open the following link in your favorite browser:
Notice the 2 parameters:
- facet=true
- facet.field=manu
If everything worked as planned, you should get an answer that looks like the one below. You should see the results show how many elements are included for each manufacturer.
…
"response":{"numFound":32,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"manu":[
"inc",8,
"apache",2,
"bank",2,
"belkin",2,
…
Facet Pivot
Pivots are sometimes also called decision trees. Pivot allows you to quickly summarize and analyze large amounts of data in lists, independent of the original data layout stored in Solr.
One real-world example is the requirement of showing the university in the provinces and the number of classes offered in both provinces and university. Until facet pivot, it was not possible to accomplish this task without changing the structure of the Solr data.
With Solr, you drive the pivot by using the facet.pivot parameter with a comma separated field list.
The example below shows the count for each category (cat) under each manufacturer (manu).
Notice the fields:
- facet=true
- facet.pivot=manu,cat
"facet_pivot":{
"manu,cat":[{
"field":"manu",
"value":"inc",
"count":8,
"pivot":[{
"field":"cat",
"value":"electronics",
"count":7},
{
"field":"cat",
"value":"memory",
"count":3},
{
"field":"cat",
"value":"camera",
"count":1},
{
"field":"cat",
"value":"copier",
"count":1},
{
"field":"cat",
"value":"electronics and computer1",
"count":1},
{
"field":"cat",
"value":"graphics card",
"count":1},
{
"field":"cat",
"value":"multifunction printer",
"count":1},
{
"field":"cat",
"value":"music",
"count":1},
{
"field":"cat",
"value":"printer",
"count":1},
{
"field":"cat",
"value":"scanner",
"count":1}]},
Stats Component
The Stats Component has been around for some time (since Solr 1.4). It’s a great tool to return simple math functions, such as sum, average, standard deviation, and so on for an indexed numeric field.
Here is an example of how to use the Stats Component on the field price with the techproducts sample database. Notice the parameters:
- stats=true
- stats.field=price
...
"response":{"numFound":32,"start":0,"docs":[]
},
"stats":{
"stats_fields":{
"price":{
"min":0.0,
"max":2199.0,
"count":16,
"missing":16,
"sum":5251.270030975342,
"sumOfSquares":6038619.175900028,
"mean":328.20437693595886,
"stddev":536.3536996709846,
"facets":{}}}}}
...
Mixing Stats Component and Facets
Now that you’re aware of what the stats module can do, wouldn’t it be nice if you could mix and match the Stats Component with Facets? To continue from our previous example, if you wanted to know the average price for an item sold by a given manufacturer, this is what the query would look like:
Notice the parameters:
- stats=true
- stats.field=price
- stats.facet=manu
…
"stats_fields":{
"price":{
"min":0.0,
"max":2199.0,
"count":16,
"missing":16,
"sum":5251.270030975342,
"sumOfSquares":6038619.175900028,
"mean":328.20437693595886,
"stddev":536.3536996709846,
"facets":{
"manu":{
"canon":{
"min":179.99000549316406,
"max":329.95001220703125,
...
"stddev":106.03773765415568,
"facets":{}},
"belkin":{
"min":11.5,
"max":19.950000762939453,
...
"stddev":5.975052840505987,
"facets":{}}
…
The problem with putting the facet inside the Stats Component is that the Stats Component will always return every term from the stats.facet field without being able to support simple functions, such as facet.limit and facet.sort. There’s also a lot of problems with multivalued facet fields or non-string facet fields.
Solr 5 Brings Stats to Facet
One of Solr 5’s new features is to bring the stats.fields under a Facet Pivot. This is a great thing because you can now leverage the power of the code already done for facets, such as ordering and filtering. Then you can just delegate the computing for the math function tasks, such as min, max, and standard deviation, to the Stats Component.
Notice the parameters:
- facet=true
- stats=true
- stats.field={!tag=t1}price
- facet.pivot={!stats=t1}manu
...
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_pivot":{
"manu":[{
"field":"manu",
"value":"inc",
"count":8,
"stats":{
"stats_fields":{
"price":{
"min":74.98999786376953,
"max":2199.0,
...
"sumOfSquares":5406265.926629987,
"mean":549.697146824428,
"stddev":740.6188014133371,
"facets":{}}}}},
{
...
The expression {!tag=t1} and the {!stats=t1} are named “Local Parameters in Queries”. To specify a local parameter, you need to follow these steps:
- Begin with {!
- Insert any number of key=value pairs separated by whitespace.
- End with } and immediately follow with the query argument.
In the example above, I refer to the stats field instance by referring to arbitrarily named tag that I created, i.e., t1.
You can also have multiple facet levels by using facet.pivot and passing comma separated fields, and the stats will be computed for the child Facet.
For example : facet.pivot={!stats=t1}manu,cat
...
"facet_pivot":{
"manu,cat":[{
"field":"manu",
"value":"inc",
"count":8,
"pivot":[{
"field":"cat",
"value":"electronics",
"count":7,
"stats":{
"stats_fields":{
"price":{
"min":74.98999786376953,
"max":479.95001220703125,
...
"stddev":153.31712383138424,
"facets":{}}}}},
{
...
You can also mix and match overlapping sets, and you will get the computed facet.pivot hierarchies.
Notice the parameters:
- stats.field={!tag=t1,t2}price
- facet.pivot={!stats=t1}cat,inStock
- facet.pivot={!stats=t2}manu,inStock
This section represents a sample of the following sequence: facet.pivot={!stats=t1}cat,inStock
"facet_pivot":{
"cat,inStock":[{
"field":"cat",
"value":"electronics",
"count":12,
"pivot":[{
"field":"inStock",
"value":true,
"count":8,
"stats":{
"stats_fields":{
"price":{
"min":74.98999786376953,
"max":399.0,
...
"facets":{}}}}},
{
"field":"inStock",
"value":false,
"count":4,
"stats":{
"stats_fields":{
"price":{
"min":11.5,
"max":649.989990234375,
...
"facets":{}}}}}],
"stats":{
"stats_fields":{
"price":{
"min":11.5,
"max":649.989990234375,
...
"facets":{}}}}},
This section represents a sample of the following sequence:
facet.pivot={!stats=t2}manu,inStock
It’s the sequence that was produced by the query shown in the URL above.
"facet_pivot":{
"cat,inStock":[{
"field":"cat",
"value":"electronics",
"count":12,
"pivot":[{
"field":"inStock",
"value":true,
"count":8,
"stats":{
"stats_fields":{
"price":{
"min":74.98999786376953,
"max":399.0,
...
"facets":{}}}}},
{
"field":"inStock",
"value":false,
"count":4,
"stats":{
"stats_fields":{
"price":{
"min":11.5,
"max":649.989990234375,
...
"facets":{}}}}}],
"stats":{
"stats_fields":{
"price":{
"min":11.5,
"max":649.989990234375,
...
"facets":{}}}}},
How about Solr Cloud?
With Solr 5, it’s now possible to compute fields stats for each pivot facet constraint in a distributed environment, such as Solr Cloud. A lot of hard work went into solving this very complex problem. Getting the results from each shard and quickly and effectively merging them required a lot refactoring and optimization. Each level of facet pivots needs to be analyzed and will influence that level’s children facets. There is a refinement process that iteratively selects and rejects items at each facet level when results are coming in from all the different shards.
Does Pivot Faceting Scale Well?
Like I mentioned above, Pivot Faceting can be expensive in a distributed environment. I would be careful and properly set appropriate facet.list parameters at each facet pivot level. If you’re not careful, the number of dimensions requested can grow exponentially. Having too many dimensions can and will eat up all the system resources. The online documentation is referring to multimillions of documents spread across multiple shards getting sub-millisecond response times for complex queries.
Conclusion
This tutorial should have given you a solid foundation to get you started on slicing and dicing your data. I have defined the concepts Pivot Facet, Stats Module, and Local Parameter. I also have shown you query examples using those concepts and their results. You should now be able to go out on your own and build your own solution. You can also give us a call if you need help. We provide training and consulting services that will get you up and running in no time.
Do you have any experience building analytical systems with Solr? Please share your experience below.