
Norconex is proud to release version 2.3.0 of its Norconex HTTP Collector open-source web crawler. Thanks to incredible community feedback and efforts, we have implemented several feature requests, and your favorite crawler is now more stable than ever. The following describes only a handful of these new features with a focus on XML configuration. Refer to the product release notes for a complete list of changes.
Restrict crawling to a specific site
[ezcol_1half]
Up until now, you could restrict crawling to a specific domain, protocol, and port using one or more reference filters (e.g., RegexReferenceFilter). Norconex HTTP Collector 2.3.0 features new configuration options to “stay on a site”, called stayOnProtocol, stayOnDomain, and stayOnPort. These new settings can be applied to the <startURLs> tag of your XML configuration. They are particularly useful when you have many “start URLs” defined and you do not want to create many reference filters to stay on those sites.
[/ezcol_1half]
[ezcol_1half_end]
<startURLs stayOnDomain="true" stayOnPort="true" stayOnProtocol="true"> <url>http://mysite.com</url> </startURLs>
[/ezcol_1half_end]
Add HTTP request headers
[ezcol_1half]
GenericHttpClientFactory now allows you to set HTTP request headers on every HTTP calls that a crawler will make. This new feature can save the day for sites expecting certain header values to be present to render properly. For instance, some sites may rely on the “Accept-Language” request header to decide which language to pick to render a page.
[/ezcol_1half]
[ezcol_1half_end]
<httpClientFactory>
<headers>
<header name="Accept-Language">fr</header>
<header name="From">john@smith.com</header>
</headers>
</httpClientFactory>
[/ezcol_1half_end]
Specify a sitemap as a start URL
[ezcol_1half]
It is now possible to specify one or more sitemap URLs as “start URLs.” This is in addition to the crawler attempting to detect sitemaps at standard locations. To only use the sitemap URL provided as a start URL, you can disable the sitemap discovery process by adding ignore="true" to <sitemapResolverFactory> as shown in the code sample. To only crawl pages listed in sitemap files and not further follow links found in those pages, remember to set the <maxDepth> to zero.
[/ezcol_1half]
[ezcol_1half_end]
<startURLs> <sitemap>http://mysite.com/sitemap.xml</sitemap> </startURLs> <sitemapResolverFactory ignore="true" />
[/ezcol_1half_end]
Basic URL normalization always performed
[ezcol_1half]
URL normalization is now in effect by default using GenericURLNormalizer. The following are the default normalization rules applied:
- Removing the URL fragment (the “#” character and everything after)
- Converting the scheme and host to lower case
- Capitalizing letters in escape sequences
- Decoding percent-encoded unreserved characters
- Removing the default port
- Encoding non-URI characters
You can always overwrite the default normalization settings or turn off normalization altogether by adding the disabled="true" attribute to the <urlNormalizer> tag.
[/ezcol_1half]
[ezcol_1half_end]
<urlNormalizer>
<normalizations>
lowerCaseSchemeHost, upperCaseEscapeSequence, removeDefaultPort,
removeDotSegments, removeDirectoryIndex, removeFragment, addWWW
</normalizations>
<replacements>
<replace><match>&view=print</match></replace>
<replace>
<match>(&type=)(summary)</match>
<replacement>$1full</replacement>
</replace>
</replacements>
</urlNormalizer>
[/ezcol_1half_end]
Scripting Language and DOM navigation
We introduced additional features when we upgraded the Norconex Importer dependency to its latest version (2.4.0). You can now use scripting languages to insert your own document processing logic or reference DOM elements of a XML or HTML file using a friendly syntax. Refer to the Importer 2.4.0 release announcement for more details.
Useful links
There is so much more offered by this release. Use the following links to find out more about Norconex HTTP Collector.
- Download Norconex HTTP Collector
- Get started with Norconex HTTP Collector
- Report your issues and questions on Github.
- Norconex HTTP Collector Release Notes
 This tutorial will show you how to extend
This tutorial will show you how to extend 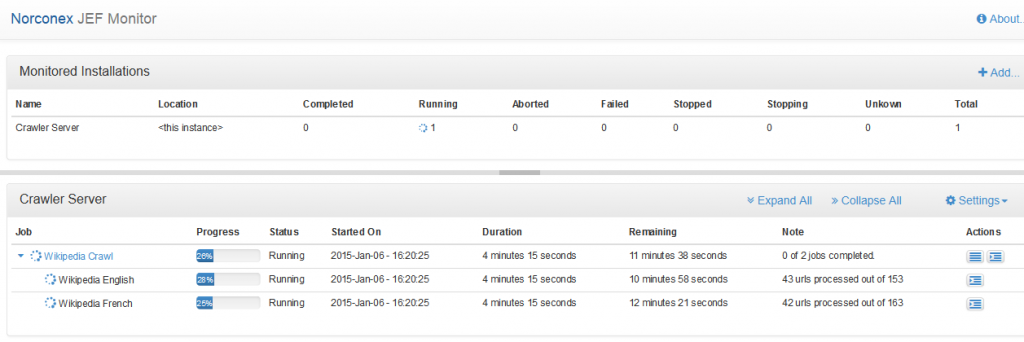

 Say hello to
Say hello to